Rivista di cultura filosofica
2017

Home
Monografie
Culture Desk
Ateliers
Chi siamo
Info

|
Semantica distribuzionale
di Andrès Reyes
1 giugno 2017
Meaning is something of a holy grail in the study of language
Magnus Sahlgren
La semantica distribuzionale nasce da un insieme di approcci allinterno della linguistica computazionale [1] e delle scienze cognitive, basati sullipotesi che i termini che tendono a ricorrere in contesti linguistici simili siano anchessi simili, anche semanticamente. Uno dei contributi più interessanti offerti dalla semantica distribuzionale è dato dalla rivoluzione copernicana che essa realizza nel rapporto tra significato e contesto. Si tratta di un aspetto dellanalisi linguistica che era stato escluso a favore dellanalisi fonetica, morfologica, sintattica e semantica. Ferdinand de Saussure, pur riconoscendo che latto della comunicazione verbale si attua nelle fasi psichica, fisiologica e fisica, non considerò linfluenza del contesto, cosa che fecero invece gli strutturalisti Leonard Bloomfield e Zellig Harris e, con la sua teoria contestuale del significato, John Rupert Firth.
CHE COSÈ UNA PAROLA? SAUSSURE E BLOOMFIELD
Lipotesi distribuzionale nasce dalle intuizioni del linguista Leonard Bloomfield, caposcuola dello strutturalismo americano, sviluppatosi fra gli anni Venti e Cinquanta, spesso in antitesi con quello europeo, che era invece più fedele allopera di de Saussure.
Durante il suo corso di linguistica generale Saussure, riprendendo i termini stoici di semainon e semainómenon e dei logici medievali signans e signatum, propose la distinzione fra significante [signifiant] e significato [signifié] come combinazione arbitraria del segno linguistico. Il primo sarebbe il sostrato fisico del segno, riconducibile allimmagine acustica, mentre il secondo ad unimmagine mentale psichica. Alla domanda: Che cosè una parola? Saussure risponderebbe: Unimmagine acustica associata a un concetto, mentre Bloomfield obietterebbe: Che cosè un concetto? Che cosè un immagine acustica mentale?
Il linguista non avendo strumenti sufficienti per rispondere a tali quesiti senza far ricorso a concetti metafisici, deve considerare il linguaggio, e solo questo, per la sua struttura. Prendiamo lesempio di un tavolo appena acquistato da Ikea. Analizzarne la struttura significa cercarne le unità minori (costituenti immediati) smontandolo pezzo per pezzo, in modo da poterlo anche rimontare sempre come tavolo rispettando la funzione di ogni singola unità. Avremo ununità che si riferisce alle 4 gambe con la funzione di sostegno, un piano con quella di ripiano orizzontale e così via. In questa prospettiva innovativa le categorie grammaticali (nome, aggettivo, verbo ecc.) dovrebbero essere riformulate in base alla loro distribuzione, cioè al fatto che possano o no occupare un certo insieme di posizioni combinatorie.
In seguito, Noam Chomsky avrebbe criticato questo approccio definendolo tassonomico, cioè focalizzato sulla ricerca di regolarità statistiche delle unità da classificare.
Lo strutturalismo americano accettò invece gli assunti di base della psicologia comportamentista e, in primo luogo, lantimentalismo, assorbendone il meccanismo di stimolo-risposta. Bloomfield, adottando una posizione di parsimonia ontologica — la concreta attività di negoziazione di significati che si compie nella comunità scientifica [2] — contro ogni interrogazione di tipo metafisico, concepisce il significato come il correlato di una rappresentazione linguistica in termini di condizionamento classico, [3] mentre lo strutturalismo europeo riconosce anche il carattere psichico del segno. Per Bloomfield il significato di unespressione linguistica sarebbe definibile come la situazione in cui il parlante lo enuncia e la risposta che esso suscita (Language, 1933) e per esemplificare la sua posizione usa un fatto linguistico:
Jill vede una mela su un albero che vuole mangiare e la chiede a Jack che, arrampicatosi sullalbero, coglie la mela e la dà a Jill (p. 22).
Quando uno stimolo esterno (S) induce qualcuno a parlare (r), la risposta linguistica del parlante costituisce per lascoltatore uno stimolo linguistico (s) che provoca una risposta pratica (R). S e R sono dunque eventi che appartengono al mondo extralinguistico, mentre r e s sono elementi dellatto di comunicazione linguistica.
IL SIGNIFICATO DALLA PAROLA ALLA FRASE: ZELLIG HARRIS
Il matematico e linguista Zellig Harris, riprendendo il lavoro del suo maestro Leonard Bloomfield, estende lanalisi strutturale di segmentazione e classificazione dalla frase al testo. Per il linguista americano due elementi si dicono equivalenti se compaiono negli stessi contesti e in Elementary transformations (1954) definisce la distribuzione di un elemento come linsieme dei suoi possibili contesti, ovvero da tutti quegli elementi che possono liberamente co-occorrere con esso, nella medesima posizione. Infine se due elementi sono equivalenti possiamo anche dedurre che lo sia anche il loro significato.
Che cosè tesgüino?
Immaginate di non aver mai sentito la parola tesgüino e che io vi dia le seguenti quattro frasi (Lin, 1998):
1. Una bottiglia di tesgüino è sopra il tavolo.
2. A tutti piace tesgüino.
3. Tesgüino ti fa ubriacare.
4. Produciamo tesgüino dal mais.
Riuscireste a comprendere il significato della parola tesgüino?
Dalle frasi date è possibile ricavare che si tratta di una bibita alcolica fermentata dal mais o intuire dal contesto ( bottiglia, ubriacare) che si tratta di un liquore come la tequila, qualcosa che si beve o una tipologia di birra.
Lo scopo di Harris è di collocare in ununica classe gli elementi che presentano la stessa distribuzione in modo tale da poter studiare la distribuzione della classe piuttosto che il singolo elemento. Ogni frase in un testo può essere rappresentata quindi come una sequenza di classi di equivalenza, linsieme degli elementi mutuamente equivalenti che si prestano ad una analisi distributiva, indipendentemente dal significato della singola parola, poiché lunità minima di significato non è più la parola, ma la frase.
TEORIA CONTESTUALE DEL SIGNIFICATO: MALINOWSKI E FIRTH
John Rupert Firth fu un linguista inglese che insegnò alluniversità di Punjab e in quella di Londra prima di recarsi alla Scuola di studi Orientali e Africani dove divenne Professore di Linguistica generale. Secondo Firth il significato di una parola dipende dal contesto situazionale in cui essa si trova riprendendo così le considerazioni etno-linguistiche dellantropologo Bronislaw Malinowski, che nel secondo volume di Coral Gardens and Their Magic (1935) aveva affermato che durante il corso della sua analisi linguistica gli era diventato via via più evidente che la definizione contestuale di ogni enunciato è della massima importanza ai fini della comprensione degli enunciati prodotti dagli aborigeni (ibidem).
La conoscenza della lingua diventa quindi fondamentale per losservazione partecipante etnografica perché permette di afferrare il punto di vista dellindigeno, il suo rapporto con la vita, di rendersi conto della sua visione del suo mondo (1922, p. 49). Inoltre, dalla ricerca sul campo, durata due anni presso gli abitanti delle isole Trobriand in Nuova Guinea, Malinowski derivò una nozione duplice di significato: in primo luogo, un enunciato appartiene a uno specifico contesto culturale [
].
Ma accanto al contesto culturale, che possiamo chiamare anche contesto referenziale, cè un altro contesto: la situazione in cui le parole sono state espresse (Coral Gardens and Their Magic, vol. 2, parte IV, 1935). Firth, come Malinowki, credeva che enunciato e situazione fossero strettamente connessi e che il riferimento al contesto fosse necessario per la comprensione del significato della parola. Firth propose inoltre unanalisi del significato che tiene conto delle proprietà associative e combinatorie delle parole, riconoscendo che è possibile conoscere il significato di una parola in base alle parole che laccompagnano: you can tell a word from the company it keeps (Firth, 1957).
***
COSTRUZIONE DI UNO SPAZIO SEMANTICO
Formalmente possiamo descrivere uno spazio semantico di parole con una quadrupla di valori: T, B, M, S (Turney, Pantel, 2010):
T è linsieme delle parole target.
B è la base che definisce le dimensioni dello spazio geometrico e contiene i contesti linguistici.
M è una matrice di co-occorrenza che fornisce una rappresentazione vettoriale di ogni parola target T.
S indica la metrica impiegata per misurare la similarità cioè la distanza tra i punti nello spazio.
Costruiamo la matrice
Ora dobbiamo rappresentare ogni parola come un vettore a n dimensioni, ciascuna delle quali conterà la frequenza con cui la parola appare in un determinato contesto linguistico definito dalla base B. Ogni parola target T corrisponderà a una riga della matrice M e le cui colonne invece agli elementi nella base B.
Utilizzando come esempio quello proposto dal linguista computazionale Alessandro Lenci, iniziamo contando in un ipotetico corpus quante volte i nomi auto, gatto, cane e camion co-occorrono con i verbi mangiare, guidare e correre, ottenendo così la seguente matrice di frequenza:
|
mangiare |
guidare |
correre |
auto |
0 |
3 |
2 |
gatto |
4 |
0 |
3 |
cane |
3 |
0 |
4 |
camion |
0 |
2 |
3 |
Per costruire i 4 vettori di auto, gatto, cane e camion utilizzeremo come primo componente la frequenza di co-occorrenza con mangiare, come secondo guidare e infine come terzo correre.
v1 = auto = (0, 3, 2)
v2 = gatto = (4, 0, 3)
v3 = cane = (3, 0, 4)
v4 = camion = (0, 2, 3)
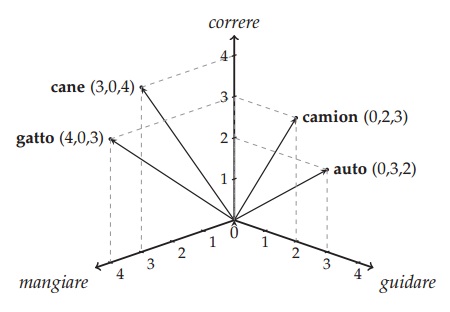 vettori in uno spazio tridimensionale
vettori in uno spazio tridimensionale
Ora dobbiamo fissare lorigine allincrocio degli assi cartesiani che saranno i contesti linguistici e le dimensioni nello spazio, invece le parole saranno punti nello spazio rappresentate come vettori, i cui componenti sono la frequenza di co-occorrenza.
Quale contesto?
I modelli di semantica distribuzionale (DSM) differiscono fra di loro per la diversa nozione di contesto linguistico, quelli più tipicamente usati sono tre:
- Document models, come la Latent Semantic Analysis (LSA) (Landauer, Dumais, 1997), le parole sono simili se appaiono negli stessi documenti o negli stessi paragrafi.
- Word models, considerano la dimensione della finestra di parole che ricorrono intorno alle parole target (Lund, Burgess, 1997; Sahlgren, 2008; Ferret, 2013).
- Syntactic models sono quelli più vicini allidea originale di Zellig Harris, perché impiegano come contesti le relazioni di dipendenza sintattica delle parole target (Curran,2004; Padó, Lapata, 2007; Baroni, Lenci, 2010).
Allinterno della cella della matrice oltre al valore della frequenza di co-occorrenza, possiamo utilizzare altri pesi statistici ( weighting) come: tf-idf, mutual information, log-likelihood ratio etc.
È meglio contare o predire?
Per la costruzione delle rappresentazioni distribuzionali possiamo impiegare due approcci distinti: count models e prediction models. Il primo approccio, che abbiamo descritto prima, si basa sul conteggio delle co-occorrenze estratte dai corpora per poi pesarle e opzionalmente idimensionarle per ottenere dei vettori densi ( dense vectors). Il secondo approccio proposto da Google (Mikolov et al., 2013), invece si basa sui prediction models cioè sulladdestrare reti neurali artificiali a predire una parola target in base al suo contesto (CBOW model) o il contesto dalla parola ( SkipGram model). Avendo così da subito vettori densi che prendono il nome di word embedding.
Regolarità linguistiche
Nel 2013 Mikolov e collaboratori hanno dimostrato che nei prediction models alcuni problemi di analogia semantica fra le parole del tipo A sta a B come C a D sono risolvibili semplicemente sommando e sottraendo le loro rappresentazioni vettoriali. Ad esempio, se prendiamo lanalogia di genere uomo sta a donna come re a regina potremmo arrivare al vettore di regina semplicemente partendo da quello degli altri vettori (uomo, donna, re) attraverso loperazione aritmetica: re uomo + donna = regina. Sottoponendo i count models agli stessi compiti dei prediction models non si registrano sostanziali differenze nelle prestazioni. Per esempio, entrambi catturano le stesse analogie (O. Levy, Goldberg, 2014). Nonostante la crescente popolarità dei prediction models, grazie anche al contributo di Google, contare e predire rimangono semplicemente due approcci diversi di costruire rappresentazioni distribuzionali, ma soprattutto due tentavi diversi di far comprendere il linguaggio umano ai computer.
[1] «Lo studio di sistemi informatici per la comprensione e la produzione di linguaggio naturale» (R. Grisham, Computanional Linguistics - An Introduction, Published by the Press Syndacate of the University of Cambridge, Cambridge 1986).
[2] S. Colazzo, Abbozzo di unontologia pedagogica, in N. Paparella (Ed.), Ontologie, simulazione, competenze, Amaltea Edizioni, Melpignao, Lecce 2007, p. 32.
[3] Nel Condizionamento Classico (Pavlov) si parla di risposta incondizionata quando ci si riferisce alla risposta (salivazione) prodotta dallo stimolo incondizionato (cibo), mentre si parla di risposta condizionata quando ci si riferisce alla risposta prodotta dallo stimolo condizionato (suono, immagine, parola).
BIBLIOGRAFIA
Baroni M., Lenci A.
– Distributional memory: a general framework for corpus-based semantics, Computational Linguistics, 2010.
Baroni M., Dinu G., Kruszewski G.
– Dont count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors, Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, 2014.
Bloomfield L.
– Language, University of Chicago Press,1933.
Curran J.R.
– From distributional to semantic similarity, PhD tesi University of Edinburgh, 2004.
Duranti A.
– Antropologia del linguaggio, trad. di A. Perri , Meltemi, Roma, 2000.
Ferret O.
– Identifying bad semantic neighbors for improving distributional thesauri, 51st Annual Meeting of the Association for Computational Linguistics, 2013.
Firth, J. R.
– A synopsis of linguistic theory 19301955, in Studies in Linguistic Analysis. Philological Society 1957, Reprinted in F. Palmer (ed.), Selected Papers of J. R. Firth. Longman, Harlow, 1968.
Harris Z.H.
– Mathematical structure of language, Wiley & Sons, New York, 1968.
Landauer T.K., Dumais S.T.
– A solution to Platos problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge, Psychological review, 1997.
Levy O., Goldberg Y,
– Linguistic regularities in sparse and explicit word representations, Proceedings of the Eighteenth Conference on Computational Language Learning, 2014.
Levy O., Goldberg Y., Dagan I.
– Improving distributional similarity with lessons learned from word embeddings, Transactions of the ACL, 2015.
Lin D.
– Automatic retrieval and clustering of similar words, in COLING/ACL-98, Montreal, 1998, pp. 768774.
Malinowski B.
– Argonauti del Pacifico occidentale. Riti magici e vita quotidiana nella società primitiva, Bollati Boringhieri, Torino, 2004.
– Coral Gardens and their Magic, American Book Company, New York, 1935.
Matthews P.
– A Short History of Structural Linguistics, Cambridge University Press, Cambridge 2001.
Mikolov T., Chen K., Corrado G., Dean J.
– Efficient estimation of word representations in vector space, Proceedings of Workshop, 2013.
Mounin G.
– Guida alla linguistica, trad. di L. Pero, Feltrinelli, Milano, 1968.
Nencioni G.
– Intorno alla linguistica, Feltrinelli, Milano, 1983.
Padó S., Lapata M.
– Dependency-based construction of semantic space models, Computational Linguistics, 2007.
Paltridge B.
– Discourse Analysis: An Introduction, Bloomsbury, New York, 2012.
Prampolini M.
– Ferdinand de Saussure, Meltemi, Roma, 2004.
Turney P, and Pantel P.
– From frequency to meaning: Vector Space Models of Semantics, J. Artif. Intell. Res.(JAIR), 2010.
Weinrich H.
– Lingua e linguaggio nei testi, trad. di E. Bolla, Feltrinelli, Milano 1988.

Piero Fornasetti, Oggetti sparsi su finto legno, c. 1960 |
|
|
|
|
